이번에는 면접에서 자주 질문을 받았던 재해복구에 대한 소개와 AWS 블로그의 재해복구 아키텍처를 정리해 보도록 하겠습니다.
재해복구란?
재해복구란 자연재해나 인간의 행동으로 인한 재해가 발생한 후 서비스에 대한 기능을 복원하는 것을 의미한다.
우리FIS 아카데미를 통해 금융권인프라에 대해 생각해보며 재해복구에 관심을 가지게되어 1차 기술세미나 주제로 재해복구 아키텍처를 소개했다.
재해복구에 가장 대표적인 사례는 바로 카카오의 사례인데 2022년 if(kakao) dev2022의 1015 장애 원인 분석 영상을 찾아보며 카카오의 서비스 장애에 대해 알아보았다.

카카오의 장애원인으로는 크게 3가지가 있는데 간략히 정리해보자면 아래와 같다.
- 데이터센터간 이중화 미흡
모든 시스템이 이중화 되어있었다면 빠르게 복구가 되었겠지만, 일부 시스템이 판교 데이터 센터 내에서만 이중화가 되어있어 특정 리소스(캐시서버, 오브젝트 스토리지)를 사용하는 카카오 로그인이나 카카오톡의 사진 전송기능이 동작하지 못했다. - 운영도구 및 모니터링 시스템의 이중화 미흡
서로 다른 데이터 센터에 이중화가 되어있는 경우에도 하나의 데이터 센터에서 장애가 발생하면 다른 데이터 센터로 자동 전환하는 시스템이 작동해야 하지만, 이 시스템마저 판교 데이터 센터 내에서만 설치가 되어있어 수동으로 전환작업을 해야 했기에 복구가 지연되었다. - 재해복구와 관련된 인력과 자원, 체계의 부족
전체시스템의 이중화 수준은 가장 약한 시스템의 이중화 수준을 따라가기 때문에 개별시스템의 미흡한 이중화가 전체적인 장애를 발생시켰습니다. 개별 부서나 시스템 마다 다른 이중화 수준, 그리고 체계의 부족으로 재해복구가 늦어졌다고 볼 수 있습니다.
제가 생각해 보았을 때 재해복구에서 가장 중요한 부분은 전체적인 서비스의 재해복구 수준유지와 재해 상황시 이를 조직에 전파하고 재해복구를 하는 프로세스가 조직에게 충분히 인지되고 있는가?에 대한 부분이 중요하다고 느껴졌습니다.
저희가 면접을 준비할때 예상되는 질문이 나오면 수월하게 말을 하는것처럼 재해복구에 대해서도 충분한 사전정비와 재해복구 시나리오에 따른 훈련이 조직내에서 충분히 이루어져야 성공적인 재해복구를 할 수 있을 것입니다.
기업의 입장에서 생각해보면 재해복구 인프라를 Active - Active구성으로 하는 경우 두 배 또는 그 이상으로 운영비용과 인프라 구축 비용이 들기 때문에 쉽지 않은 결정이라고 생각합니다.
AWS 재해복구 아키텍처
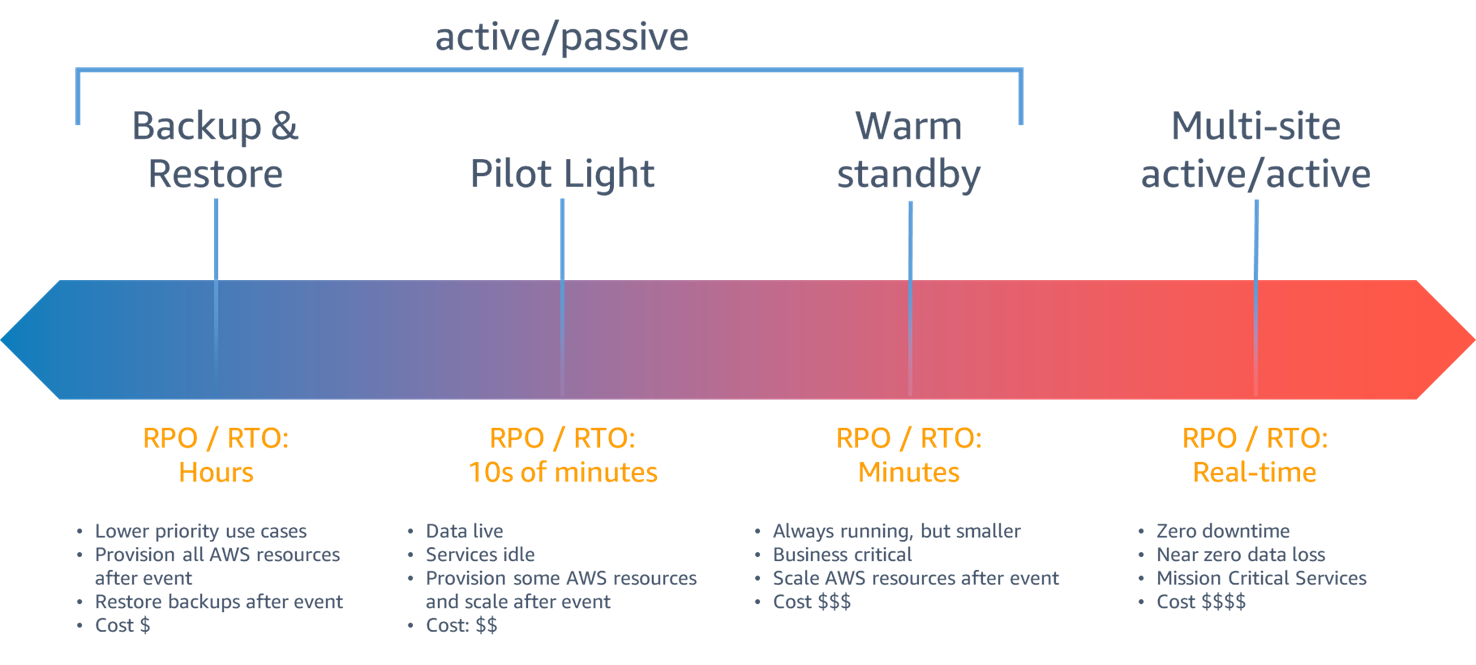
AWS의 재해복구는 RPO/RTO에 따라 AWS Backup & Restore, Pilot Light, Warm standby, Multi-site active/active 전략으로 나누어져 있고 앞의 3개의 전략은 Active - Standby전략이며 Multi-site active/active전략은 이름 그대로 Active-Active 구성입니다.
그러면 그에 대한 아키텍처와 전략에 대해 알아보도록 하겠습니다.
Backup & Restore
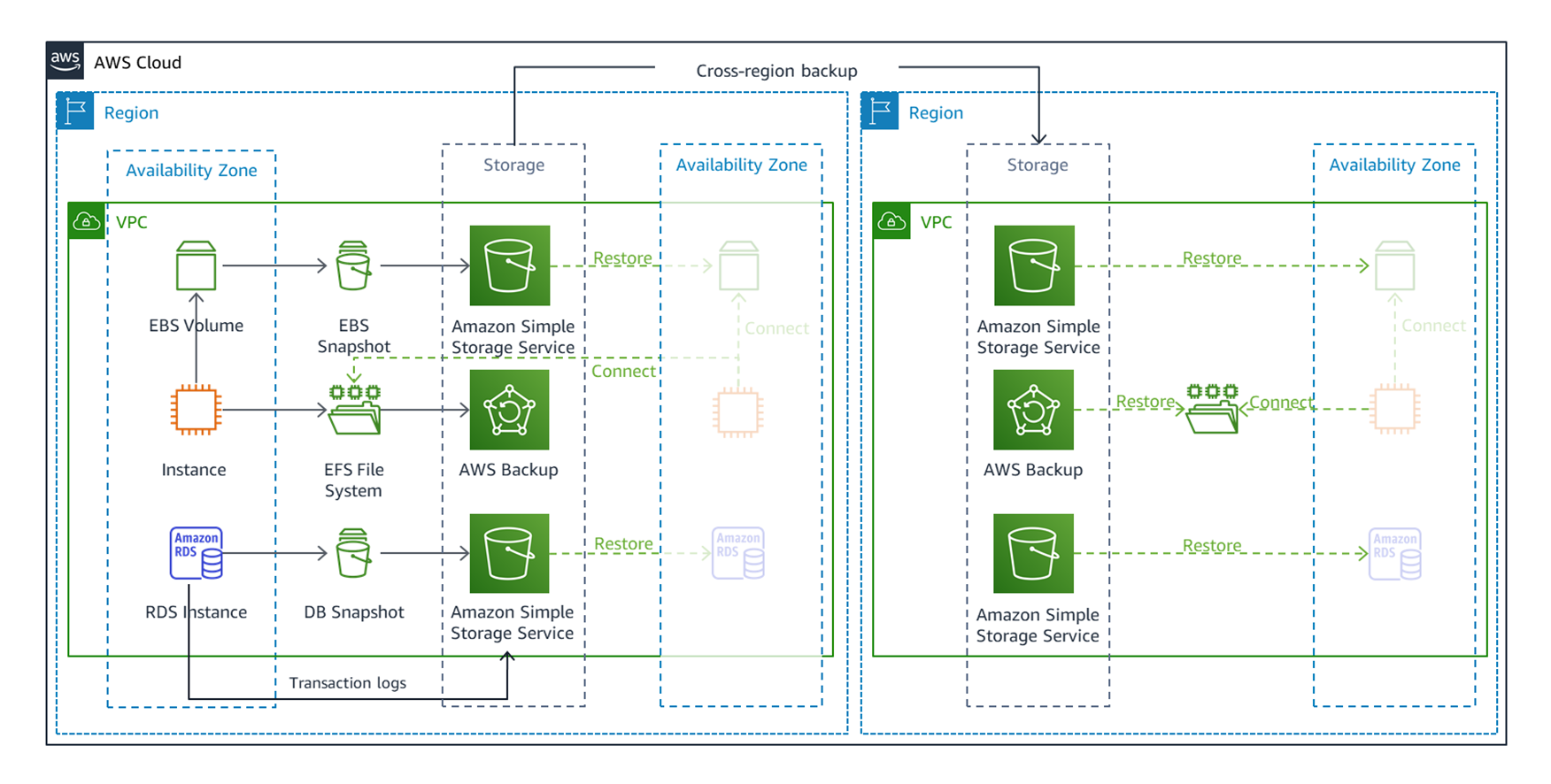
가장 먼저 Backup & Restore 전략입니다. 해당 전략은 AWS의 스토리지 서비스인 S3와 EFS, EBS등과 같은 스토리지 서비스를 사용하여 백업을 진행하고 재해발생시 백업데이터를 이용하여 복구를 진행하게 됩니다.
다른 방법대비 높은 RPO와 RTO를 가지고 있어, 재해 복구시 속도가 느리고 데이터 유실이 있을 수 있지만, 가장 적용하기 쉽고 저렴한 방법입니다. 재해가 발생하면 저장된 백업 데이터를 토대로 백업리전의 인프라를 복원해야합니다.
서울과 일본의 오사카리전을 예로 들자면 서울에서 서비스를 사용하고 있다면 왼쪽에서 서버, 디비를 통해 작업을 수행하며 데이터들은 EBS, S3등에 저장되게 됩니다. 그러면서 AWS Backup을 사용하여 DB의 스냅샷, 파일, 스토리지등을 오사카 리전에 이를 백업시켜 놓아 서울의 데이터 센터에 재해가 발생했을 때 백업된 데이터를 토대로 인스턴스 및 DB를 생성하여 서비스를 복구하게 됩니다.
이 때 AWS Backup 사용시 원본이 아닌 복제본을 사용하여 서비스를 복구하게 됩니다.
Pilot Light
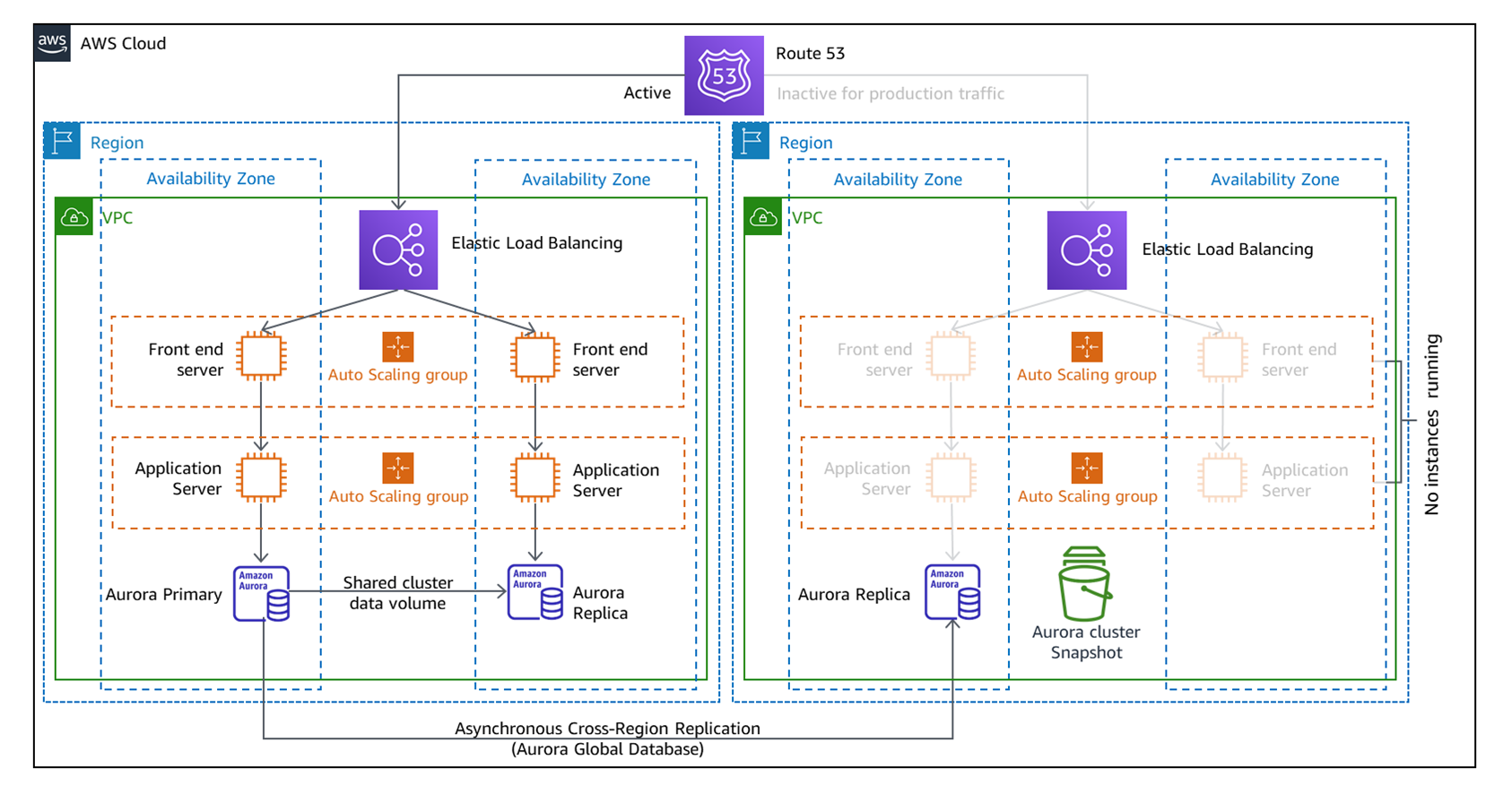
Warm Standby
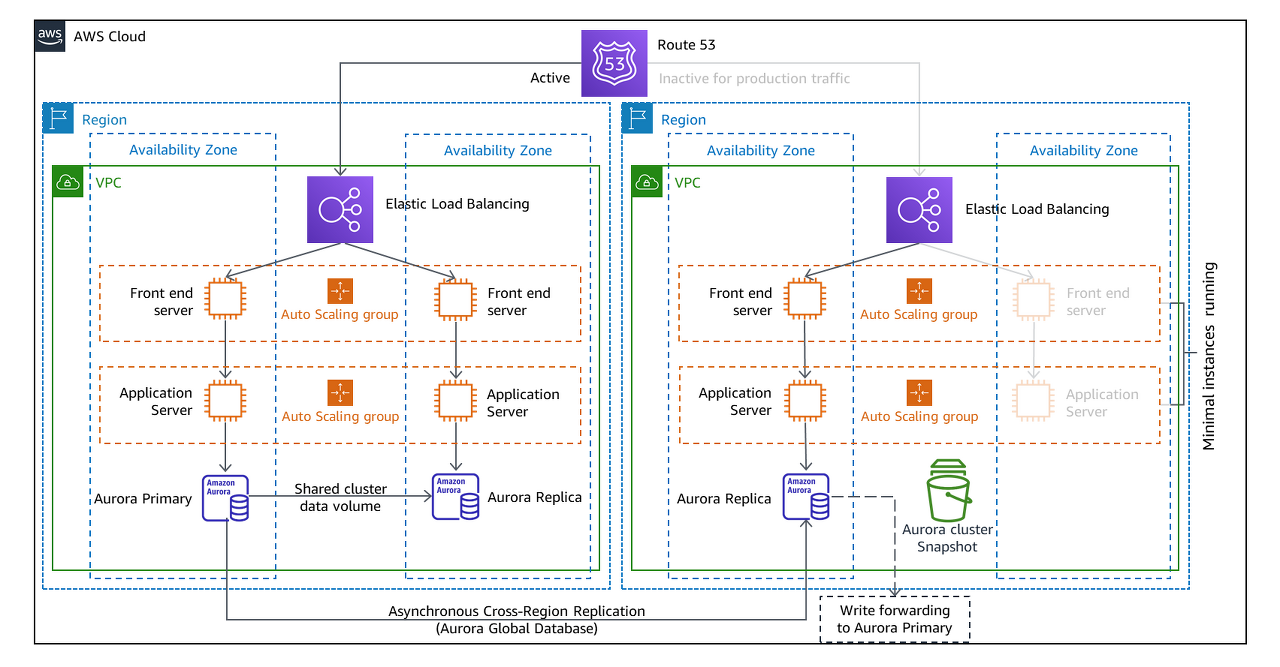
다음은 Pilot Light와 Warm Standby전략입니다. 해당 전략들은 전체적인 구조는 동일하지만 인프라 구성에서 차이가 있는데요, 운영하고 있는 리전의 데이터를 실시간으로 복구될 리전에 복제합니다. 추가로 복구리전에서도 지속적으로 백업을 생성하여 사람의 실수로 데이터가 삭제되거나 잘못된 데이터를 복구에 사용하는것을 방지합니다.
두전략모두 서브넷 및 라우팅이 구성된 VPC와 로드밸런서, 오토스케일링그룹과 같은 인프라 요소가 포함되어 더욱 빠른 복구시간을 제공합니다.
여기서도 마찬가지로 서울리전과 오사카 리전을 예로 들자면 평상시에는 좌측에 있는 서울의 인프라와 데이터를 이용하여 서비스를 하고 데이터를 오사카에 복제를 해 놓습니다. 여기서 복제된 데이터를 하나만 두지 않고 사람의 실수로 인해 오사카에서 잘못된 데이터를 백업하거나 삭제되는 경우를 막기위해 오사카에서는 추가로 데이터에 대한 백업을 스냅샷 형태로 저장해 놓습니다.
Warm Standby전략과 Pilot Light전략의 차이는 Standby중인 인프라 구성요소에 실제 서비스처럼 동작할 수 있는 수준의 인프라를 생성해 놓는다는 것 입니다. 물론 원본과 똑같은 수준이 아닌 적은 용량을 가지고 있어 트래픽을 동일한 수준으로 처리할 수는 없지만 재난 발생시 최소한의 인프라가 존재하기때문에 파일럿라이트에 비해 더 빠른 복구시간(RTO)을 제공합니다.
Multi-site active/active

마지막으로 멀티사이트전략은 가장 낮은 RPO와 RTO를 제공합니다. 하지만 두개 이상의 리전에서 시스템을 운영하기에 운영복잡성과 비용이 크게 증가하게 됩니다. 기본적인 인프라 구성은 Pilot Light와 Warm Standby전략과 유사하지만 서비스를 두개 이상의 리전에서 처리한다는 가장 큰 차이점이 존재하며, 데이터는 각 리전에서 실시간으로 복제되어 주기적으로 백업됩니다.
재해과정을 조직에 알리는 방법?
재해상황을 조직에 알리는 과정에는 여러방법이 있겠으나 제가 참고한 AWS 블로그의 자료에는 아래의 과정을 따릅니다. 저는 이러한 과정이 조직 내에서 어떠한 형태로든 존재해야 한다고 생각하며 자동화가 되어있으면 좋겠죠...??
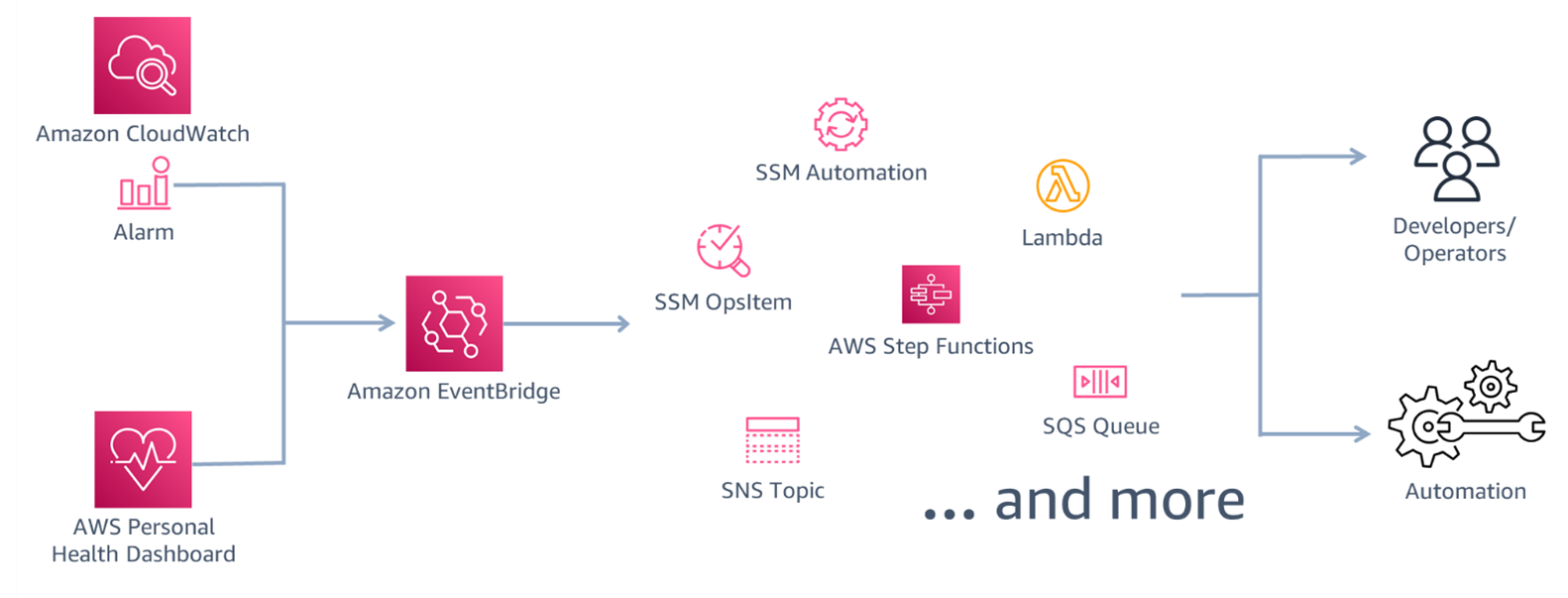
재해복구시간은 재해발생에서부터 이를 감지하고 복구리전으로의 시스템 전환 및 이에 필요한 의사결정과정을 모두 포함합니다. CloudWatch를 통해 클라우드 리소스와 실행중인 애플리케이션을 모니터링하여 여러 지표를 수집하고 이를 로그파일로 저장하여 시스템에 대한 경보를 설정하고 Personal Health Dashboard를 통해 서비스에 영향을 미치는 여러 이벤트를 보여주며, AWS지원팀과의 연계를 통한 필요한 지원 및 리소스를 얻을 수 있습니다.
위와 같은 모니터링 시스템을 이용하여 재해발생을 감지하여 Event Bridge에서 발생한 이벤트들로부터 다양한 서비스(슬랙채널, 이메일)를 트리거 시켜 관리자에게 알림을 전달하고 자동 복구 프로세스를 시작할 수 있을것 입니다.
지금까지 AWS 재해복구에 대해 간략히 알아보았는데 재해복구와 관련한 디테일한 부분은 AWS 블로그를 참고해주시고 다음 포스팅에서는 기존의 재해복구 단계인 Mirror, Hot, Warm, Cold Site의 내용에 대해서도 작성해 보겠습니다.
'클라우드 > AWS' 카테고리의 다른 글
| [AWS] EC2 key없이 접근하기 - ssh 설정 변경 (0) | 2025.05.03 |
|---|---|
| [Devocean, AWS] 데보션 마지막 스터디 - AWS 네트워크 (0) | 2024.08.03 |
| [AWS] S3 + Vue CI/CD 프론트 배포하기 (3) | 2024.07.24 |
| [AWS, 재해복구(DR)] AWS재해복구(DR) 아키텍처 - 2편 (1) | 2023.12.21 |
| [AWS] AWS SAA-C03 자격증 후기 (1) | 2023.11.11 |